My Good Faith Critique Of DRA

Note: This isn’t a Tigers post. If you’re here for the Tigers, feel free to ignore. Also, I’m publishing this here rather than at FanGraphs because 1) I don’t want the general public to get the idea that FanGraphs as an institution is throwing shade at DRA and 2) I don’t want the perception that anything I’m saying is done in the service of driving traffic or subscriptions to or from either site.
Evaluating pitchers is very hard, but that hasn’t stopped people from trying. Wins and losses. ERA. WHIP. FIP. These are all statistics that at one point or another had been at the forefront of the quest for The Best Single Metric. A wise person might suggest that searching for one metric to rule them all might be a silly quest, but even if we all decided to properly use every tool in the toolbox, there would still have to be a best metric among the useful ones.
Two years ago, the Baseball Prospectus stats team took a swing at building the next generation of pitching metrics, led by their top-line creation, Deserved Run Average (DRA). Many in our little corner of the world treated this as near second coming because it was first high-level attempt to get beyond the FIP-generation of metrics and some of the smartest people in the public analysis sphere had thrown their intellectual heft behind the effort.
DRA promised to incorporate a lot of information that hadn’t found its way into FIP while also taking a more complex approach to modeling the pitcher-value process. I agree that those are worthwhile goals.
I think FIP is a very useful metric, not just because it does a pretty good job of representing pitcher value but because it is extremely straightforward. I am not saying that simplicity makes FIP a good metric, but rather that its clarity does. FIP has flaws, but its flaws are in perfect view. I know exactly what FIP is doing and exactly what FIP is not doing. And this is precisely where DRA has so far failed to win me as a full convert so far.
I want to be clear that I am not saying DRA is less rigorous than FIP or that it has been designed poorly or in bad faith. My issue with DRA is not that I think there is something wrong with it, it’s that I don’t really know what to make of it. My argument is not that FIP is a better representation of pitcher value than DRA, it’s that I am less certain about the quality of DRA than I am the quality of FIP.
Imagine FIP and DRA are diamonds. I can hold FIP in my hand and examine it under a magnifying glass. DRA is on a table twenty feet away. I can see the exact quality of the FIP diamond, but I can only tell that DRA is a diamond. Smart people who cut the DRA diamond are telling me they think the DRA diamond is better, but I have not been able to see them side by side.
In my own analysis and in my own writing, I have utilized DRA but I still lean heavily on the FIP-family of metrics for this reason. If I’m writing about a player and want to communicate something, I prefer FIP to DRA because I can talk clearly about what FIP says. If I want to use DRA I can only say that based on the complex method it deploys, the pitcher is this good/bad/other.
Now many strong advocates of DRA will tell you that its complexity is good. Pitching, after all, is very complicated so it follows that any statistic that measures pitching holistically should also be complicated. That’s a very convincing point, but as I noted earlier my problem is not complexity, it’s clarity. I love complicated things. I’ve taken graduate-level courses in statistics and modeling. I am in no way turned off by DRA in concept. At no point in this piece am I saying DRA should be less complex.
However, there are two clear issues with DRA that prevent me from using it as my primary point of reference. The first is that the BP team has not outlined a justification for its modeling strategy. If you read through their explanations (see here, here, here, and here) what you find is a list of flaws that exist with other pitching metrics. “FIP doesn’t have X, X matters, so we put X in our model. We know pitchers control their BABIP to some degree, so we put that in the model.”
This creates a couple of issues. The first issue is that I can’t see what components are doing the lifting (for example, this page needs to be way more granular). Does a player have a good DRA because their opponents are very tough or because their defense is terrible? DRA jams a lot of information into a single output and that makes it quite difficult to use in any sort of interesting way. FIP only has five inputs (strikeouts, walks, hit batters, home runs, and balls-in-play) and even that can feel overly aggregated. DRA has even more inputs that have run through even more aggregation. That might provide DRA with a more accurate output but it blurs a lot of lines. This pitcher might be good, but I have no idea why he’s good.
More importantly, however, is the fact that the BP team has not thoroughly explained why their modeling choices (structure, not inputs) are the proper modeling choices. DRA is a complex model, and while complexity is good, complexity also means that there were hundreds of choices made along the way that could have made differently and produced differently outcomes. In other words, DRA is built on a lot of choices made by people about how to incorporate something and those choices have not been explained and defended. As I noted earlier, the choices may be correct, but I have no way of evaluating them if they do not explain how they came to them.
Here’s an excerpt from the Gory Math DRA post:
What is the best way to model this relationship? That required a lot of testing. A LOT of testing. We tried linear models. We tried local regression. We tried tree-based methods. We bagged the trees. We tried gradient boosting. We tried support vector machines. We even tried neural networks. None of them were providing better results than existing estimators. And then we tried the one method that turned out to be perfect: MARS.
MARS stands for Multivariate Adaptive Regression Splines, and was introduced by Dr. Jerome Friedman of Stanford in 1991. You don’t hear much about MARS anymore: it has been supplanted in the everyday modeling lexicon by trendier machine-learning methods, including many of those we mentioned above. But MARS, in addition to being useful for data dumpster-diving, also has another big advantage: interactions.
MARS uses what are known as regression splines to better fit data. Instead of drawing a straight line between two points, MARS creates hinges that allow the line to bend, resulting in “knots” that accommodate different trends. The power of these knots is enhanced when MARS looks at how variables interact with each other. These interactions are, in our opinion, one of the under-appreciated facts in baseball statistics.
As discussed above, pitchers who are pitching particularly well or poorly have a cascading effect on other aspects of the game, including base-stealing. Moreover, there is a survival bias in baseball, as with most sports: pitchers who pitch more innings tend to be more talented, which means they end up being starters instead of relievers or spot fill-ins. The power of MARS is it not only allows us to connect data with hinged lines rather than straight ones, but that it allows those hinges to be built around the most significant interactions between the variables being considered, and only at the levels those interactions have value. MARS also uses a stepwise variable selection process to choose only the number of terms sufficient to account for the most variance.
Most people won’t be able to make heads or tails of this section and it’s incumbent upon BP to make it more accessible, for one. But even granting a pardon for that, as someone knowledgeable in these issues, I don’t know if this strategy is a good one or a bad one. They made all sorts of choices based on various tests and I am simply asked to accept they chose the right one and that there isn’t a better option out there.
Now you might say that it isn’t their job to teach me how to literally write R code and test my own model so that I can probe the ether for things I think might be imperfect within DRA. Of course they shouldn’t be asked to test literally every possible model specification when building DRA, but you have to give me more information about why you chose to build it like this as opposed to some of the other approaches you tried or could have tried.
On the other hand, with something like FIP, all of the decisions are on display. You might think the decisions are wrong, but you can see the decisions and make that judgement. There are five inputs with a set of clear weights. That’s all FIP is, and while that limits FIP in terms of accuracy, FIP is extremely clear. I can’t make that judgement with DRA. A stronger and clearer defense of the specifications needs to be made.
And this leads me to my second key issue with DRA that prevents me from using it in a more serious way. DRA is two years old and has already had three major iterations that worked differently in meaningful ways. I have no problem with updating your metrics based on new data or new research, and I don’t think there is an inherent problem any of the specific changes they have announced. The problem is that DRA-2015, DRA-2016, and DRA-2017 have different views of the same seasons and I have a strong suspicion that DRA-2018 will lead to more of these cases.
The rapidity with which DRA has been revised indicates the BP team’s willingness to explore improvements (which is great!) but it also suggests to me that they haven’t figured out the right way to model the underlying data generating process.
When they announce a revision, they are stating that the previous version failed to capture something they found essential. It’s one thing if these changes were exclusively based on new data, but they are also based on changes to the modeling. And if the results are that sensitive to tweaks in method, I am suspect about the entire system. That doesn’t mean that FIP is necessarily better than any particular version of DRA, simply that I know that in a few months DRA is going to change and a pitcher I thought way decent might actually be kind of bad even though we didn’t learn anything new about the pitcher himself.
Put another way, are the things BP learned about DRA between 2015 and 2017 things they couldn’t have learned by exploring more specifications before the initial rollout? I am not saying they should hold the release back until it’s perfected because public input makes things better, but simply that the first few years are more akin to a beta test. I’m not ready to fully adopt the metric until it settles in a little more. That’s not me dismissing DRA or its potential value to the world of baseball analytics. I really like DRA from a conceptual perspective, but my perception is that the nuts and bolts are subject to change quite frequently, so I have yet to dive in without a life preserver.
I want to reiterate that none of this is a critique of any individual decision and it is decidedly not an argument that FIP is a better representation of pitching value than DRA. That is a separate argument that can be had on separate terms. But I do think that DRA is not as useful as FIP at this point in time. I am hesitant to use a metric whose workings I can’t see. I don’t know if the modeling strategy is correct and I am pretty sure that in a few months a chunk of pitchers will have totally different DRAs.
I also want to be clear that none of this is intended as shade or inter-nerd sniping. I have great respect for the BP stats team and have shared these critiques with them. This is not a take down, it’s a list of demands.
I think DRA is aiming in the right direction, I just haven’t been given enough information to figure out if it’s really an improvement over its predecessors. Building a metric like DRA makes all the sense in the world and some great people are in command, but it will remain a complementary metric for me until it is unpacked in a way that allows me to trace its design.
So here is what I would propose:
- Create an expanded version of the DRA run value page that includes every individual component so that people can see how the different factors are operating. It takes two seconds to figure out why FIP likes someone or doesn’t. Doing so with DRA is next to impossible.
- Go back to the drawing board on the public facing explanation and give clearer explanations of how DRA works and why it works that way. DRA is complex, but you can explain complex things in a clear manner if you break it down into less complex pieces and work with outsiders to ensure they follow the explanation at each step.
- If DRA is meant to be a living, breathing statistic that gets updated annually, then be willing to accept ongoing skepticism about the execution of the statistic. If you are rejiggering it frequently, then the audience is going to wonder if the current version is the right one. If you want to avoid that, you have to change the name each time you change the stat. I get that this is annoying, but it’s part of the job.
This Is The Moment To End The Closer Role
Things are not going well for Francisco Rodriguez. He’s allowed 12 runs in 11.2 innings and he has a 159 FIP-. He has five meltdowns already (appearances with -6% WPA). He’s given up runs in eight of his 13 outings, including five runs against nine batters in two blown games over the weekend. His grip on the closer’s role is precarious to say the least. Brad Ausmus, king of having confidence in his closer, no longer has confidence in his closer. The press is circling the wagons. You can feel a change coming, and the obvious candidate is Justin Wilson who has allowed just eight base runners in 13.2 innings this season.
At this moment, the question the Tigers brass are asking is whether they should replace K-Rod with Wilson. Demoting the closer is a big deal in the modern game. Once you say it out loud, you can’t put it back. So the Tigers are proceeding with caution, but you can feel it coming. Do we replace the closer?
But I want to suggest another path: Don’t.
You initial reaction might be, “but K-Rod is pitching very poorly, we can’t keep putting him into crucial situations?” to which I would reply that you’re absolutely correct. The Tigers should stop giving all the save chances to K-Rod, but they should also decline to name a new closer and should resist the urge to simply replace one failed closer with a bright, shiny new closer. Now is the moment to give up on the closer role entirely.
I’ve been harping on this generally for years, but let me hit some highlights. First, saves are stupid. They are artificially constructed and not a measure of anything particularly important. You can rack up a bunch of saves without pitching that well if you’re coming into games with the bases empty and a three run lead. Conversely, you don’t get saves for getting out of big jams if you happen to do so an inning or two early.
Second, being a slave to the save leads managers to pigeonhole their best reliever into an inefficient role. The ninth inning is the most important inning in some games, but it’s not the most important inning in every game. Sometimes the game is on the line in the 7th or 8th and if you have a closer whose job it is to get saves, you won’t use them in these earlier situations.
Teams would be much better off if managers would be willing to deploy their relievers in the right spots, based on matchup/leverage/etc rather than rigid inning-based roles.
Now the naysayers will tell you that relievers thrive when they’re given a specific role because it helps them prepare. Yet there are two key flaws in this logic. The first flaw is that you can give relievers defined roles without one of those roles being the arbitrary “save situation.” Even if you think lining guys up ahead of time is beneficial, there are better ways to do it. But the second flaw is more compelling. Relievers spend their early careers being used in all sorts of roles until they wind up “sticking” in their 7th, 8th, or 9th inning roles. The system is backwards because it sorts the best relievers into rigid roles while giving the worst relievers no structure. The best relievers should be the ones who can handle some uncertainty in their deployment because they have the experience and talent to handle it.
And the entire concept of roles is foolish more broadly. I don’t doubt that relievers like having a target in mind for when they’re going to pitch, but I refuse to believe elite competitors are so fragile that they can’t handle that target moving around depending on the situation. Instead of having a “closer,” you could communicate to your pitchers before the game that they are likely to be used in a particular spot, such as “the first sign of trouble” or the “first clean inning after we pull the starter.” “We’ll use you in the 8th or 9th if it’s within two runs.” I appreciate the idea that pitchers like to get into their pre-appearance mindset in a certain way, but these are grown men who are capable of handling a little uncertainly. All it takes is some good communication between them and the manager.
For all these reasons, teams should abandon the concept of a closer and relievers who have certain innings. Teams should deploy relievers based on who the best available player is at any given time. But this week I came up with another reason that make a lot of sense. If you don’t have a closer, you don’t have this defining moment where the manager has to announce that he’s demoting his relief ace to a lesser role. It sure seems like it would be a lot better for everyone involved if Ausmus could casually give K-Rod fewer high leverage innings rather than having to officially announce a change. If Ausmus was sometimes using K-Rod in the 9th but also using the Wilsons quite often, it wouldn’t be a big deal to push K-Rod down the pecking order. If all the pitchers were sharing different innings depending on the exact conditions, you wouldn’t have all this pressure on K-Rod to keep his job and the constant questioning about whether Brad believes in him.
I don’t think the Tigers will actually adopt this mindset, but it’s definitely time. It’s a more efficient way to deploy your relievers and it seems a lot easier to handle struggling pitchers when you don’t this big production about whether they’ve been bounced from their role or not. I’m assuming Justin Wilson will get the next save chance for the Tigers, but we’d all be a lot better off if he didn’t get all of the save chances going forward.
James McCann’s Framing Problem

A few nights ago, Rod Allen made a comment to the effect that “James McCann is going to be the Tigers catcher for many years to come.” I believe he said this in the context of Avila’s hot start, but regardless of his exact phrasing or what prompted it, Allen was offering a pretty common sentiment: McCann is the long-term answer at the position.
I’ve written on a number of a occasions that I’m a little shaky on that proposition. Yes, McCann has a strong throwing arm, but he otherwise hasn’t demonstrated the kind of talent that should keep the Tigers from considering alternatives. It’s well documented that in his first season, McCann struggled to receive pitches in a way that maximized strikes. At the time, I made the case for patience. I wasn’t ready to say McCann wasn’t a good receiver just because he was terrible at it during his first season. And last year, McCann took some steps forward, leading me to pen this May 2016 piece on the ways he had improved. He was getting more called strikes in and out of the zone and had particularly improved on his glove side.
When you add everything up, Baseball Prospectus said McCann went from costing the Tigers about 15 runs relative to average in 2015 to being right about average in 2016. McCann didn’t become a good framer, but he definitely performed better. And that makes sense. Not only did McCann have time to learn his staff and settle in, he had another year working with Brad Ausmus, who was a talented framer in his day. This fits a neat and tidy narrative and it made us feel great. The flip side was that McCann went from an iffy bat in 2015 to a terrible one in 2016, but I’m always willing to give young catchers a break on their hitting as they adjust to the rigors of major league duty.
So I was interested to watch McCann in 2017 because while it’s hard to measure the total impact of framing in real time, it has a huge impact on the game. The difference between a ball and strike aggregated over thousands of opportunities makes a difference and if McCann had actually improved his talent level in 2016 that was a big deal. However, it was possible that McCann had simply performed better in 2016 for any number of reasons and he would regress toward the mean in 2017.
If we look only at the overall BP metric, the signs are not good. McCann has already been worth -3.3 runs in 1,284 chances. If we pro-rate that to about 6,400 chances (the average he had in 2015 and 2016), we get about -16 runs. On a per pitch basis, that’s worse than 2015!
Granted, I’ve long been a proponent of caution when looking at these aggregated framing metrics. I think the models are missing some important aspects and don’t quite control for everything that should control for, but they are generally good enough to separate bad, decent, and good. But like I did last May, I want to look a little deeper to see what’s happening.
Unfortunately, MLBAM changed a bit of the coding on Baseball Savant so you’re going to see different 2015/2016 numbers than in the previous posts if you followed the links, but the meaning isn’t going to change so we can roll with it.

The basic lesson here is that McCann clearly improved on the edges of the zone in 2016 and has fallen back in 2017. MLBAM now has a zone breakdown which includes specific zones for the edges, so let’s explore that:

I looked at called strike rate in the 11, 12, 13, 14, 16, 17, 18, and 19 zones. It’s compelling.

Let’s look at them individually, but I’ll constrain it to 2016 vs 2017. Small sample caveats apply.
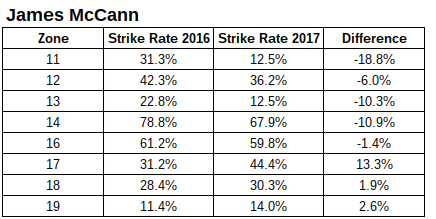
If you compare the table to the image, you can see that McCann has done a bit better on the low edge, but on the glove size and top of the zone he’s done much worse. I don’t want to put too much of a focus on these chunks, but you can get a sense of the problem. This tracks pretty well with his historical problems.
It’s too early in the year to call this McCann’s 2017 level and there’s no reason to trust 2017 a ton more than 2016, but this is something to watch. McCann has hit for power and showed more discipline this year, but even with some quality early season swings he hasn’t even reach league average at the plate (although his BABIP will come north over time). But if McCann is going to frame this poorly, it would take some great hitting to compensate and he isn’t there. He’s got a great arm, but catchers are judged by the gloves and their game-calling, and at least of those aspects of his game isn’t looking great so far.
