Stat(s) of the Week: Defensive Runs Saved and Ultimate Zone Rating

Since I’ve twice written above defense in the last week, it’s high time I actually explain these defensive stats. Luckily, this is quite easy to explain and understand. There are two primary defensive metrics that people use. Defensive Runs Saved (DRS) and Ultimate Zone Rating (UZR), which are based on people watching video of every play and computer algorithms.
You can learn exactly how each is calculate here, DRS and UZR. But you don’t need to know how to calculate them in order to understand what they mean. It’s important to learn about these because Fielding % is problematic stat because it doesn’t factor in a player’s range, so you can have a good fielding percentage if you don’t make errors because you never get to difficult balls. We need numbers that measure how good players are at preventing runs and avoiding errors isn’t the only way to do that.
The numbers are scaled to position, so league average at every position is zero and positive numbers are good and negative numbers are bad.
For example a player with a +5 DRS or +5 UZR is five runs better than league average at their position. 10 runs is equal to 1 Win Above Replacement (WAR). These are counting stats, so you accumulate them as the season goes on, although I believe they are only updated weekly on the more popular statistics websites.
You can use either DRS or UZR depending on your preference, but Baseball Reference uses DRS in their WAR and Fangraphs uses UZR in theirs. It’s a preference thing. I always use Fangraphs WAR on this site, but I interchange the defensive stats on occasion because I don’t really have a favorite. If there is no label on this site, it is UZR.
Additionally, you might see UZR/150, which is simply UZR scaled into a full season of games as if you played at your current pace for a whole season.
As a rule of thumb, 0 is average, -5/+5 is above or below average, -10/+10 is poor or great, -15/+15 is awful or elite. It is also important to know that these statistics take a while to become predictive, so small samples can cause problems with defensive numbers but they generally all a good description of what has happened, even if it doesn’t predict what will happen next.
Evaluating Defense: Web Gems or Advanced Metrics
I’m a huge believer in the value of defense in baseball and I’m also someone who believes in advanced statistics in baseball. You might already know that if you’re a regular reader. Some of the typical advanced stats regarding defense are Defensive Runs Saved (DRS), Ultimate Zone Rating (UZR), and UZR’s close cousin UZR/150 which scales that number based on a full season of games.
Critics and proponents alike will tell you these numbers aren’t perfect and do not always predict true skill in small samples, but they are reasonably good compared to any other defensive statistic we have and they are created by people watching baseball, not a computer algorithm. So they’re the best measure of defense we have even if there are flaws.
But another measure of defense is the number of spectacular, eye-popping plays. This measure is called the Web Gem and is brought to you by the people at Baseball Tonight.
Mark Simon, an ESPN Stats and Info researcher, often posts Web Gem data on Twitter and I’ve been wondering about Web Gems and advanced stats for a while. Today I stopped wondering and started doing. Here’s Simon’s most recent tweet regarding team level Web Gems:
Now if you’re a real scientist who knows about probability and stuff, you know there are a couple flaws in what I am about to do. Let me get them out of the way quickly:
- Web Gems are conditional what happens on a given day, the 6th best play (not a gem) on Monday might have been 1st on Tuesday (a gem) but due to the random distribution of gems, it doesn’t qualify even though it should.
- Terrible defensive plays don’t count against you in Gems, but do in DRS/UZR
- Team numbers aren’t best, but it’s all I have. A team’s defensive quality can vary, so if one play accumulates all of your gems they can still only account for a fraction of your DRS/UZR
So recognize that these are issues, but also ignore them for now because this is supposed to be fun and merely to satisfy my curiosity.
How well do Web Gems predict defense? Does a small number of great plays predict overall defensive value? The short answer, no. Not at all. Here is Web Gems plotted against DRS, UZR, and UZR/150.
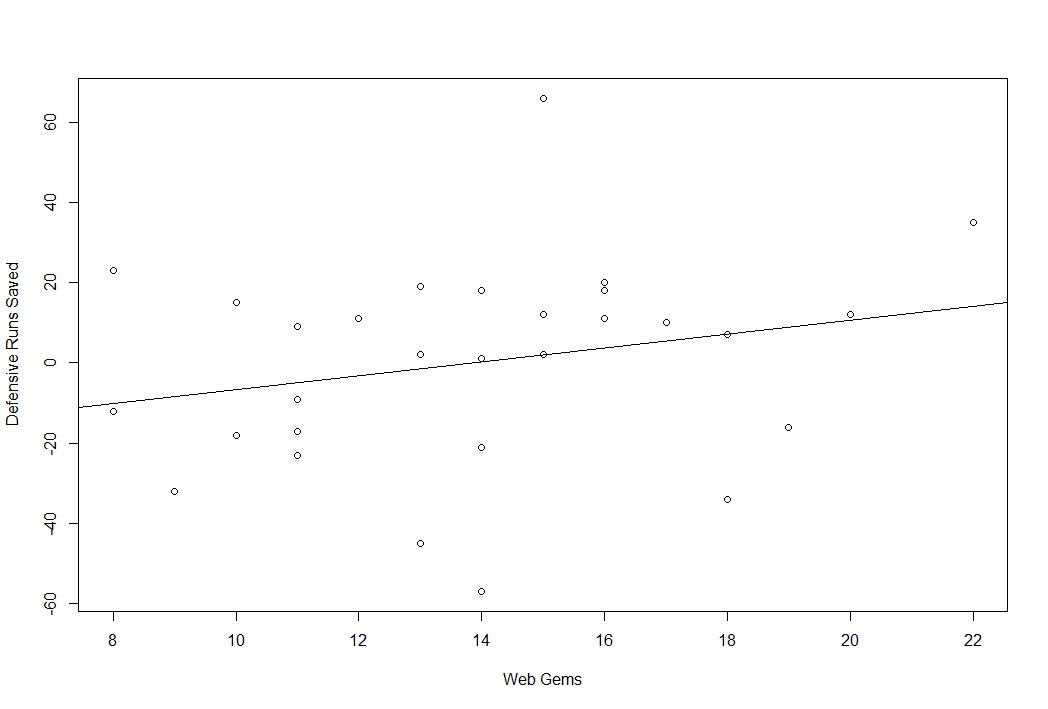
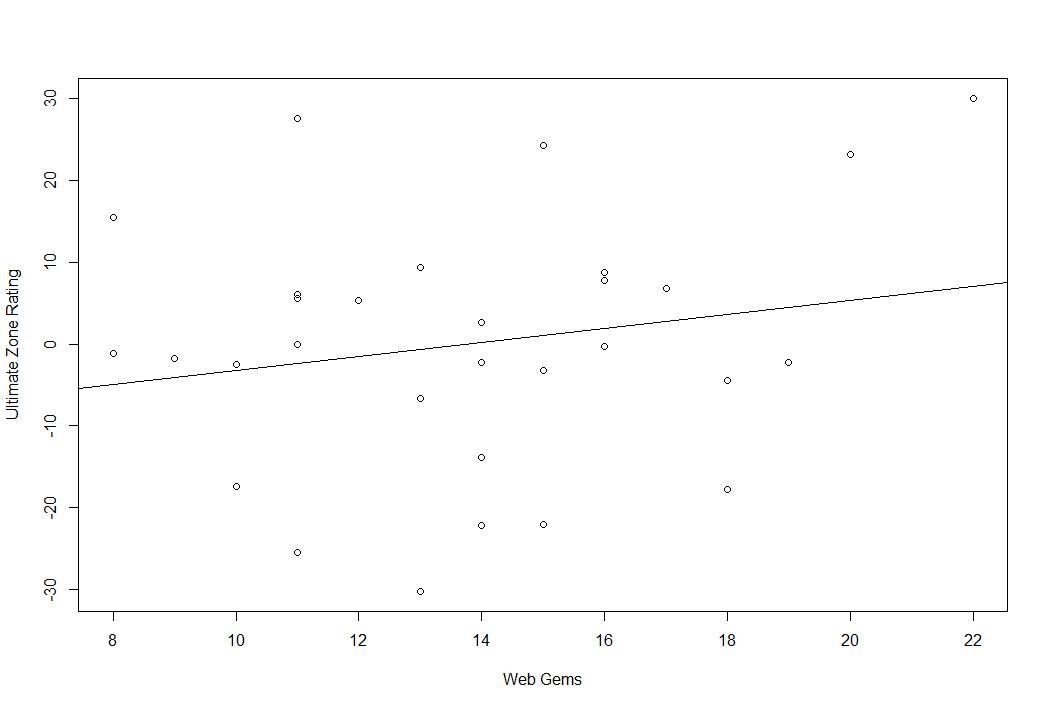
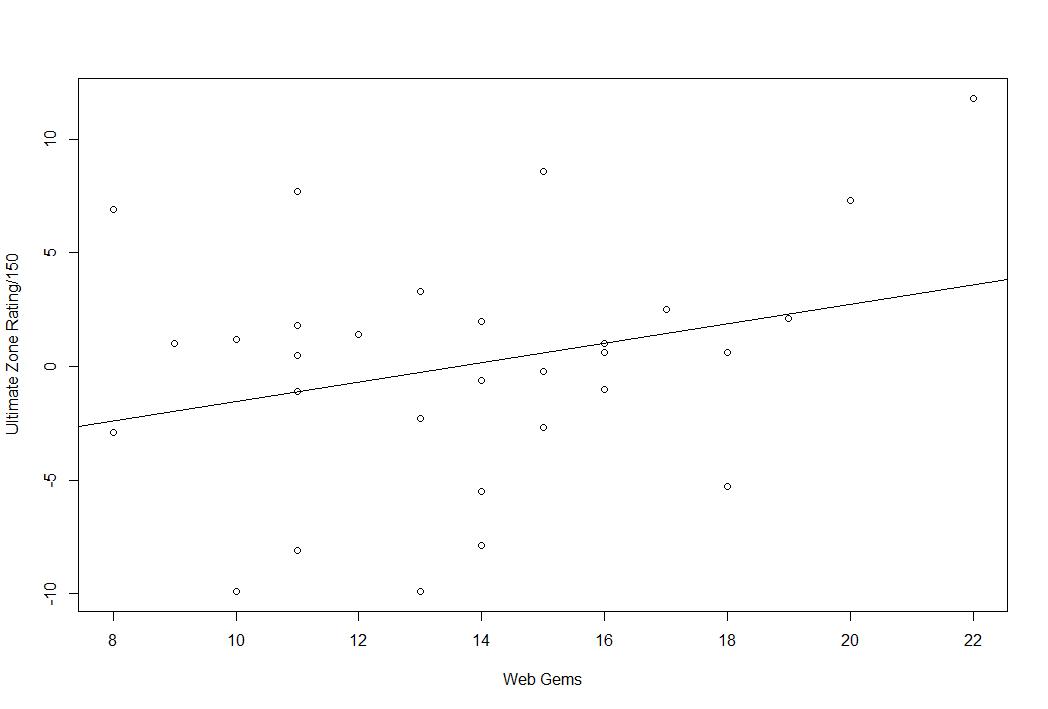
You may notice the line slops upward in each graph, meaning that as Web Gems increase, so too do the various metrics, but a positive slop doesn’t mean it’s a real effect. That’s just the line of best fit. In reality, these lines are not statistically significant. In fact, they are almost as insignificant as something can be (I know that’s bad statistical theory, it’s poetic license).
Here are the slope coefficients, standard errors, and adjusted r squares:
| WEB GEMS | DRS | UZR | UZR/150 |
| Parameter Estimate | 1.70 | 0.86 | 0.43 |
| Standard Error | 1.30 | 0.80 | 0.27 |
| Adjusted R squared | 0.03 | 0.00 | 0.05 |
As you can see, the adjusted r squares for each of these are remarkable tiny. In layman’s terms, what you are seeing here is this. More Web Gems, on average, mean higher DRS/UZR, but this is almost surely due to random chance. Web Gems also explain less than 10% of the overall variation in the defensive stats.
Basically, the takeaway here is that overall team defense is not related to a team’s overall number of Web Gems. That might not interest you, but I was curious. I’d like to do it with every player in the league, but I don’t have complete individual Web Gem data and I think the very high number of zeroes would probably make it a giant mess. I’m not sure.
But my curiosity has been satisfied and I feel better knowing that the ability to make ridiculous plays is not strongly related to the overall ability prevent runs.
Stat of the Week: Weighted Runs Above Average (wRAA)
When we talk about offensive statistics, the ones we usually talk about on New English D are wOBA and wRC+ which take the actual value of each offensive action and weight them properly, which OBP and SLG do not do. I encourage you to clink the links and read about those statistics if you have not already done so. However, those two statistics are rate stats and not counting stats. Rate stats tell you how well a player has performed while they’ve been on the field, but counting stats are also good for telling you how much value a player has actually added to his team.
If you have a 150 wRC+, but only have half the plate appearances of someone with a 120 wRC+, you’re not as valuable. You need to be both a good performer and a player who stays healthy and on the field. With that, I’ll introduce Weighted Runs Above Average (wRAA) to do just that. Weighted Runs Created (notice the absence of the plus sign) is a similar statistic, but it is just scaled differently. The concept is the same, but let’s stick with wRAA.
wRAA is the offensive component of Wins Above Replacement (WAR) and is based on wOBA and is rather simple to calculate if you have all of the necessary numbers.
((wOBA – League Average wOBA)/wOBA scale) * (PA)
A player’s wOBA and PA are pretty obvious and the league average and wOBA scale be found for each season quite easily here. The idea behind this statistic is how many runs a player is worth to his team above average and ten runs is equivalent to one WAR. Here is the full explanation from Fangraphs but the idea is pretty simple. How many runs above average has a player been worth to his team. Average, therefore, is 0 and anything above 10 is good and above 20 is great. It is also a counting stat, so players accumulate them throughout the season as opposed to wRC+ and wOBA which are rate stats.
I generally like rate stats better, but counting stats are an important comparison. Here’s a quick example:
Miguel Cabrera has a 193 wRC+ and .456 wOBA in 325 PA while Matt Tuiasosopo has a 186 wRC+ and .446 wOBA in 88 PA. Cabrera and Tuiasosopo have very similar rate stats, but you can distinguish their value based on how many PA they have using wRAA. Cabrera has 36.9 and Tuiasosopo has 9.3.
I wouldn’t tell you to use wRAA over wRC+ or wOBA, but it is nice to use in tandem if you’re trying to compare which players have been more valuable to their team, but stick with the rate stats if you care about determining who is actually the better player.
Stat of the Week: Run Expectancy
A point of contention among members of the baseball community is bunting. Most sabermetricians would tell you that the sacrifice bunt is overused because it gives away an out while a lot of on-field Dusty Baker/Harold Reynolds type people love bunting to move runners closer to the plate. I’m not here to argue for or against bunting, but rather to offer you a tool for determining the answer for yourself. This tool is a Run Expectancy Matrix.
The idea behind Run Expectancy is figuring out how many runs, on average, a team scores in a given situation (based on the number of outs and which bases are occupied). The values are based on long run averages and you can calculate them based on many years or a single year, but the ratios are generally going to be the same. Presented below is the matrix from 2012. What you see in the grid is the expected number of runs a team will score given the situation as presented by the top row and left column. You can use the RE Matrix to determine which strategic move is best for you.

So let’s use an example. Runner on 1st base, no outs. At this point, the team is expected to score .8577 runs this inning because, on average, teams have scored that many runs in the inning after those situations have occurred. If we were to sacrifice bunt in this situation, we would move to runner on 2nd, 1 out, which has an expected run value of .6551. That’s obviously less than .8577, so the sacrifice bunt in that situation is not the right play on average. You can play around with other situations on your own.
An important caveat is that this chart is context neutral and reflects averages. If the baserunner is Austin Jackson and the guy bunting is Miguel Cabrera, you’re hurting yourself more than if the runner is Victor Martinez and the bunter is Ramon Santiago. You should be more willing to give up an out to move a runner if the batter is more likely to make an out. However, that doesn’t mean it’s necessarily ever the right play to give up the out. A pitcher who hits .150 is almost definitely going to make an out, so you want him to move the runner up, but Miguel Cabrera is pretty likely going to get a hit relative to average, so you don’t want him intentionally making an out.
I don’t mean to suggest that you should take these numbers as gospel, but rather that you should be aware of which situations lead to the most runs and which situations you want to get yourself into if possible. The takeaway here is that we know how many runs a team is likely to score in a given situation and we can make some sort of educated prediction about what will happen if we do something else. Context matters, but this matters too.
I’m generally not a fan of the sacrifice bunt (or conversely the intentional walk), but there are occasional situations in which it makes sense. This RE Matrix should help you better understand which situations call for which moves.
As always, if you have questions about how this works or how to use it, feel free to comment or contact us. Also, please let us know if there is a statistic or sabermetric concept you’d like to learn about and we’d be happy to cover it.
Stat of the Week: Expected Fielding Independent Pitching (xFIP)
Generally, I’ve been a little light on “weekly” updates to this feature, but I generally write at least one statistically informative post a week, even if it doesn’t actually follow the mold I’ve laid out. Today, I’ll try to write that wrong with an introduction to the very useful Expected Fielding Independent Pitching (xFIP).
You may recall my introduction to Fielding Independent Pitching (FIP) some months ago and my frequent use of the metric on the site. You can read my introduction to FIP or Fangraphs’ primer to catch up, but I’ll outline the basic concept because it carries over.
We use FIP because ERA is not a reflection of a pitcher’s individual performance because he cannot control what his defense does once the ball is put in play. Two pitchers who are carbon copies of each other will perform differently if you put them in front of the Dbacks defense (currently the league’s best) and the Angels defense (one of the league’s worst so far) despite throwing identical pitches to identical hitters. ERA is a reflection of the team as a whole, not just the pitcher.
In steps FIP or a class of numbers coming from this idea, to measure a pitcher’s performance based only on what we know he can control. FIP takes strikeouts, walks, and homeruns and uses historic run values to calculate a number on the same scale as ERA so that you can see which pitchers are succeeding in the areas of the game they can control. Generally speaking, defense evens out over a long enough period and ERA, FIP, and our new friend xFIP will converge toward each other.
The FIP formula looks like this:
FIP = ((13*HR)+(3*(BB+HBP))-(2*K))/IP + constant
So what exactly is xFIP? xFIP, as you can read about on Fangraphs, takes this one more step. xFIP is the same as FIP except it normalizes HR/FB rate to give you a number that better predicts future performance.
It’s actually pretty simple, just stay with me. Generally speaking, we’ve found that the percentage of a pitcher’s flyballs that are hit for homeruns will converge toward about 10% and that large variations from that number are not sustainable. If you allow more flyballs, you’ll allow more homeruns, and that will cost you in FIP and xFIP, but if you’re allowing half of your flyballs to go for homeruns, it’s likely that won’t happen for very long.
So xFIP looks like this:
xFIP = ((13*(Flyballs * League-average HR/FB rate))+(3*(BB+HBP))-(2*K))/IP + constant
As you can see, it’s the same formula, but it takes your flyball rate and multiplies that by the league average HR/FB rate to get a more predictive version of your HR rate going forward. xFIP is one of the best indicators of future performance we have and it is very useful in evaluating which pitchers are getting lucky and which pitcher’s are actually performing in line with their skills.

If we scan the Tigers 2013 leaderboard right now (digits truncated), you can get a sense of how this works. As expected, all of the Tigers have better FIP than their ERA because they play in front of a poor defense, but all of their xFIP are slightly higher than their FIP (except for Porcello) because they are allowing a lower than average HR/FB rate. Porcello, on the other hand, has very unlucky 21% HR/FB rate, so his xFIP is better than his FIP. Again, xFIP correlates better with future performance than almost any other ERA estimator.
Personally, I like to look at FIP to see how a pitcher is doing and use xFIP to see how fluke-y his homerun rate is. They’re both good metrics and they are both better indicators of individual performance than ERA.
Want to learn about a statistic? Request one for the next edition in the comments section or on Twitter @NeilWeinberg44. If you’re looking to catch up on sabermetrics, check out New English D’s posts on FIP, WAR, wOBA, wRC+, and ISO.
On Defense and Unearned Runs: ERA Isn’t the Answer
Last night, Justin Verlander was not at his best, but his overall line looked worse than it was because Torii Hunter made two poor plays in right that cost Verlander two runs, but neither was ruled an error. So Verlander’s ERA goes up because of poor defense even though conventional wisdom is that the “earned” part of ERA factors out your defense making mistakes behind you.
It does and it doesn’t. You don’t get charged for runs that come from errors but you do get penalized when the official scorer makes a mistake (as we saw last night) and when your defensive players do not make a play they should have even though it does not qualify as an error. Sabermetricians have devised other metrics like FIP, xFIP, SIERA, and others to stand in for ERA with a focus on elements of the game that pitchers can control because they have no control of what happens once contact is made. (Read my explanation of FIP for more specific information)
Today, I’d like to offer a little concrete evidence for why ERA doesn’t capture a pitcher’s value. Let’s take an independent measure of defense (Fangraph’s aggregate Fld score) and compare it to the number of unearned runs a team allows (or the percentage of a team’s runs that are unearned).
I haven’t looked back into history, but for 2013 the relationship is nonexistent. For the raw number of unearned runs, the results are not statistically significant and are substantively small. On average a team needs to increase its Fld score (range -21 to 18 so far) by about 7 to eliminate a single unearned run on average (range 5 to 25 so far). On average, from worst to first in Fld you can move only 20% of the range of unearned runs. This tells us that the strength of one’s defense does not predict the number of unearned runs allowed. The results are the same if we control for the total number of runs a team has allowed.
Here it is in graphical form:

As you can see, the number of unearned runs has almost no relationship with Fld and if you squint hard enough can only come up with the slightest negative tilt. Basically, what this is showing you is that the difference between your runs allowed and the runs you get shoved into your ERA do not depend on the quality of your defense, it depends on the official scorer and it depends on a lot of other things that have nothing to do with a pitcher’s skill or performance.
This is all by way of saying that ERA is not a good measure of a pitcher’s true skill level. It’s not a bad place to start, but if you look at the Won-Loss Record and ERA, you’re getting very little useful information. Expand your horizon to K/9, BB/9, HR/FB, FIP, xFIP, and other statistics and metrics that enrich the game.
ERA attempts to capture the pitcher’s performance in isolation but it doesn’t. The defense and the official scorer play huge roles in determining that number. If you want to judge a pitcher by themselves, you need to look deeper.
If you’re interested in learning more, I encourage you to visit the Fangraphs Glossary or to post questions in the comment section. I’d be happy to explain or interpret any and all statistics about which you are curious.
The Greg Maddux Way: A Simple Statistic
The great Greg Maddux (355-227, 3.16 ERA, 3.26 FIP, 114.3 WAR) once said the key to pitching is throwing a ball when the batter is swinging and throwing a strike when the batter is taking. That’s a pretty good general rule, but an astute observer would certainly recognize that a pitcher isn’t really equipped to predict such a thing terribly well.
But this did get me thinking, is there something to this idea despite other intervening reasons that confound it? Certainly, if you have a crazy slider that no one can hit, it doesn’t really matter where you throw it. Or a fastball that the hitter can’t handle. It’s also not like where you choose to throw the pitch and if the hitter swings are independent of each other.
So this is an exercise, plain and simple. The Maddux idea is a good one in principle, but it’s not that simple. We know that, he knows that, let’s just look into it for fun.
I drew from the 2012 season and looked at qualified pitchers (n = 88). I developed a simple statistics to quantify how Maddux-y they pitched.
mPercentage = (O-Swing% – League Average O-Swing%) + (-1)*(Z-Swing%-League Average Z-Swing%)
O-Swing% is the percent of the time a pitcher induced the opposing hitter to swing at a pitch he threw outside the zone and Z-Swing% is the same statistic for pitches inside the zone. The -1 is included so that both Maddux attributes are positive and can be added together without converging toward zero.
The results were pretty surprising because some pitchers at the top of the list are awesome and some are average and some are terrible. There isn’t a ton of correlation between this statistic and actual production. The two league leaders in 2012 mPercentage are Joe Blanton and Chris Sale. Cliff Lee is 4th, which sounds right, but Verlander is 42nd.

If you take a wider angle and regress ERA or FIP on mPercentage, you find that on average a 1% increase (i.e. 5% to 6%) decreases your ERA or FIP by 0.06 runs, which is not very much at all. mPercentage is statistically significant in both models, but not substantively significant at all. (The R squared is less than .11 in both.)
So what this tells us is that the Maddux Method doesn’t really exist in practice. Pitchers who induce swings on balls and takes on strikes are no more successful than those who do not. However, there is a obviously a two-way street at play here like I mentioned earlier. The Maddux Method works perfectly in theory, but we have an observation issue given that Justin Verlander’s strikes are much harder to hit than Joe Blanton’s, so he can throw more of them.
I like the Maddux philosophy of pitching, but it isn’t enough. You also need to have good stuff.
Stat of the Week: Isolated Power (ISO)
This should be a very straightfoward Stat of the Week because it is something you can easily calculate at home without any sort of complex math. This week, we’re talking about Isolated Power (ISO) which measures how good a player is at hitting for extra bases.
You’re likely more familiar with Total Bases (TB) which is a counting stat that picks up on a similar concept. ISO is essentially Slugging Percentage with the singles stripped out.
ISO = (2B+2*3B+3*HR)/AB
A rule of thumb scale puts average ISO around .145 and anything about .200 being great. You read Fangraphs’ write up on the subject here.
I wouldn’t recommend looking at ISO over wOBA or wRC+, but it I would look at it in addition to those two metrics. It can provide you a nice piece of information about how frequently a guy hits for extra bases. It contains the same problem that slugging percentage does in that it weighs doubles, triples, and homeruns improperly, but it’s a good way to separate how much of a player’s slugging percentage is driven by a high rate of singles versus real extra base power. It’s also not a particularly predictive stat over a small sample if you’re concerned about that type of thing.
For reference, the top 5 players by ISO from 2012 were: Josh Hamilton, Edwin Encarnacion, Miguel Cabrera, Ryan Braun, and Josh Willingham.
Stat of the Week: Weighted Runs Created Plus (wRC+)
After a break during the offseason, our Stat of the Week series returns today with an important offensive metric know as Weighted Runs Created Plus (wRC+). You can find this metric on Fangraphs with a full explanation here.
Last season I broke down wOBA which is OPS on steroids. The wOBA idea feeds into wRC. What wRC+ tells is how much better a player is than average when it comes to producing runs for his team. Simpler yet, it’s a catch all offensive metric that can be used for easy comparison between players.
Like WAR, this isn’t a perfect tool, but through some calculations based on the historical value of each plate appearance outcome, we can get an estimate of how much value a player brings to his team. League average wRC+ is scaled to 100, meaning that a player with a wRC+ of 120 is 20% better than a league average hitter. wRC+ is also adjusted for park and league effects, so if you play at Petco Park, you get a little boost because the park suppresses offense.
For reference, both Miguel Cabrera and Mike Trout posted wRC+ of 166 in 2012. The most average players in 2012 by wRC+ were Brett Lawrie and Rickie Weeks. Let’s look at Lawrie’s line to illustrate. He hit .273/.324/.405 with 11 HR in 536 PA. That looks about right for league average. wRC+ tells us Cabrera was 66% better than that, which makes sense given a .330/.393/.606 line.
You’ll need a big enough sample for wRC+ to tell you anything meaningful in a predictive sense, but as the season wears on take a look at the wRC+ leaderboard to get a sense of who the best offensive contributors are.
I encourage you to go back and read my wOBA breakdown because it stresses the idea that OBP and SLG are improperly weighted when you add them together to get OPS because a double isn’t really worth twice as much as a single. wOBA gives you a better answer to the question OPS tries to answer, and wRC+ scales it to league and park averages.
Go explore wRC+ for yourself and feel free to post any questions you may have. We at New English D are big believers in sabermetrics, not because we want to boil the game down to a spreadsheet, but because we always want more information about the game. More stats and metrics are a great way to learn more about the game and evaluate what you watch.
Skeptical? Here are the best 8 players by wRC+ last season: Cabrera, Trout, Braun, Posey, McCutchen, Fielder, Encarnacion, and Cano. The math might scare you off, but don’t let it. Just learn how to read the output. You don’t have to buy into everything you see on a sabermetric site, but I think that if you try it, you’ll like it. There is a ton you miss by staying with the traditional stats. And who wants to miss baseball?
Calculate it yourself!
Fangraphs and Baseball Reference Unify Replacement Level
Today, Fangraphs and Baseball Reference consummated a relationship we knew to be coming for the last few weeks. While the two sites have always calculated Wins Above Replacement (WAR) differently, they decided to discuss reworking a component of the metric. That component was replacement level, defined as the production of a player who is readily available as a minor league free agent or on the waiver wire.
Today it happened. Dave Cameron can give you all the specifics over at Fangraphs, and I can’t say I disagree with any of the changes. I like that the two leading sites are working to improve WAR and our overall statistical evaluation of baseball. This is a step in the right direction and it’s good for everyone involved.
But there is a weird result from today’s unveiling of the new replacement level that is freaking me the hell out.
Everyone’s WAR is slightly different than it was yesterday.
Now many who hate sabermetrics might use this as a point of assault, but those people who know better know that it’s just a shifting baseline calculation that marginally changes the precise point value of WAR. The substantive results are the same, just refined.
But for someone who reviews baseball statistics quite religiously, it’s trippy. For example, Justin Verlander gained 0.2 WAR for 2012. Buster Posey lost 0.4 WAR. Most of the exact changes are pretty small and don’t change the interpretation much, but when we’re dealing with something like WAR that is imprecise and on a relatively small scale, things get funky. A bunch of players shifted places in rankings. Not dramatically, mind you, just from 2nd to 3rd or 8th to 7th. It’s minor and doesn’t mean much, it’s just weird.
I woke up today and the past had changed. I mean, I know that isn’t true, but it seems like it. Justin Verlander was the best pitcher by WAR last season, but now he is the best by more. Perhaps this means nothing to anyone else, but it was interesting for me.
WAR got better today and given the people in charge of its design, it will continue to get better into the future. Let’s just hope I’m better prepared to cope next time and don’t spend an hour of my day staring at my computer repeating “this is weird” to myself.
But seriously, it was.
