12 Other Reasons To Kill The Win

Over the last few weeks I’ve been breaking down reasons to ignore the pitcher win and I think the case is pretty airtight. First I gave you the 9 best seasons under 9 wins, then I gave you the 9 worst 20 win seasons, and showed you that wins do not even out over a career. Finally, I presented a case study in wins using Cliff Lee and Barry Zito’s 2012 season. The evidence is clear, wins do not reflect individual performance and shouldn’t be used as such. But if you’re not convinced, read this and tell me what you think (all numbers for starting pitchers from 2013 entering 6/13):
- A pitcher has gone 6+ IP and allowed 0 ER and not earned a win 68 times.
- If you lower that to 5+IP and 0 ER, it goes up to 82 times.
- A pitcher has gone 6+ IP and allowed 4 or fewer baserunners and not earned a win 50 times.
- A pitcher has gone 6+ IP, allowed 4 or fewer baserunners AND allowed 0 ER and not earned a win 20 times.
- A pitcher has gone 8+ IP and allowed 1 or fewer ER and not earned a win 23 times.
- A pitcher has gone 8+ IP and allowed 1 or fewer ER and earned a LOSS 4 times.
- A pitchers has gone 5 IP or fewer and allowed 10 or more baserunners and earned a win 29 times.
- A pitcher has gone 6 IP or fewer and allowed 5 ER or more and earned a win 12 times.
- A pitcher has allowed 6 ER or more an earned a win 7 times.
- A pitcher has walked 6 or more batters and earned a win 9 times.
- A pitcher has allowed 12 baserunners or more and earned a win 23 times. Only two of them went 7 or more innings.
- A pitcher has gone 7+IP with 10+ K, 2 or fewer BB, and 3 or fewer ER and not earned a win 28 times.
So let’s review. You can have a great season and win fewer than 9 times. You can have a below average season and win 20. You can have a much better career than another pitcher and finish with the same winning percentage. A pitcher can dramatically out pitch another and have way fewer wins in a season. And finally, the above 12 things can happen…before the All-Star break.
I’ll close with this. In 2012 a pitcher went 7 or more innings and allowed 0 ER 363 times. They didn’t earn a win 57 times in those starts. Do we really care about a statistic that says a pitcher who goes 7 or more innings while allowing 0 ER shouldn’t get a win 16% of the time?
I know I don’t.
Stat of the Week: Batting Average on Balls in Play (BABIP)
Batting Average on Balls in Play (BABIP) is one of the most easily understood sabermetric statistics because it can be easily calculated at home like many of the basic descriptive stats, but it is also a very powerful tool. Let’s start with the basic idea (or you can read about it at Fangraphs).
BABIP is exactly what it says it is, a player or pitcher’s batting average (or average against) on balls that are put in play, meaning that strikeouts and homeruns are subtracted from at bats in the denominator while sacrifice flies are added and homeruns are subtracted from the numerator of batting average, it looks like this:
BABIP = (H – HR) / (AB – K – HR + SF)
Sac bunts aren’t included because you’re making an out on purpose, so it doesn’t really belong given that it doesn’t reflect a hitter or pitcher’s skill.
BABIP tells you what percentage of balls hit somewhere the defense could make a play go for hits and can tell us a lot about players. For hitters, defense, luck, and skill determine your BABIP. A good defense playing against you will lower your BABIP because they will catch balls that should be hits, luck will lower or raise your BABIP because sometimes hard hit balls go right at someone, and skill will influence your BABIP because line drive hitters and speedy runners are more likely to have higher BABIPs because they hit the ball in a way that is more likely to result in hits or they leg out infield singles.
We generally think of true talent levels for hitters between .250 and .350 with average being right around .300. If you see someone deviate greatly from .300 or so, there may be a legitimate reason, but it is also very likely about luck. Hitters can influence their BABIP, but BABIP is fluky and takes a while to settle down, meaning that in small samples your BABIP can be quite different from your true talent level. This is what we mean when we say someone’s success is BABIP driven. No one can sustain a .450 BABIP for a whole season, but they can do it for two weeks and that can inflate statistics like batting average and slugging percentage in small samples.
The same is true for pitchers, but it’s even more critical. Pitchers have very little control over what happens to the baseball once it is put in play. Strikeouts, walks, and homeruns rest solely on a pitcher, but once a hitter makes contact it’s out of their hands. Most pitchers will have BABIPs close to .300 and any serious deviation from that number means there is some serious luck or defense involved. Even pitchers who are easy to hit will still have BABIPs closer to average because their defense will still get to a high percentage of balls in play.
Using BABIP is very easy. Hitters can have higher or lower BABIPs based on their skills, but they are unlikely to post very high or very low BABIPs. For example, only 14 hitters in MLB history have BABIPs above .360 for their careers and only 26 hitters since WWII have BABIPs lower than .240. What you want to do is compare a hitter’s season BABIP to their previous seasons to see if it is in line. If you’re jump from a .310 career BABIP to a .360 the next season, it’s likely due for some regression to the mean. BABIP can be predictive like this if there is no underlying change in skill.
For pitchers it’s even better. If a pitcher has a BABIP the deviates heavily from average, it’s almost certainly a function of luck or bad defense.
It’s quite straightforward. If someone’s BABIP deviates heavily from .300 and has no history of a high or low BABIP, it means you’re likely looking at something fluky. Here’s a quick demonstration to prove the point. Here is every qualifying hitter season since 1990 by BABIP:
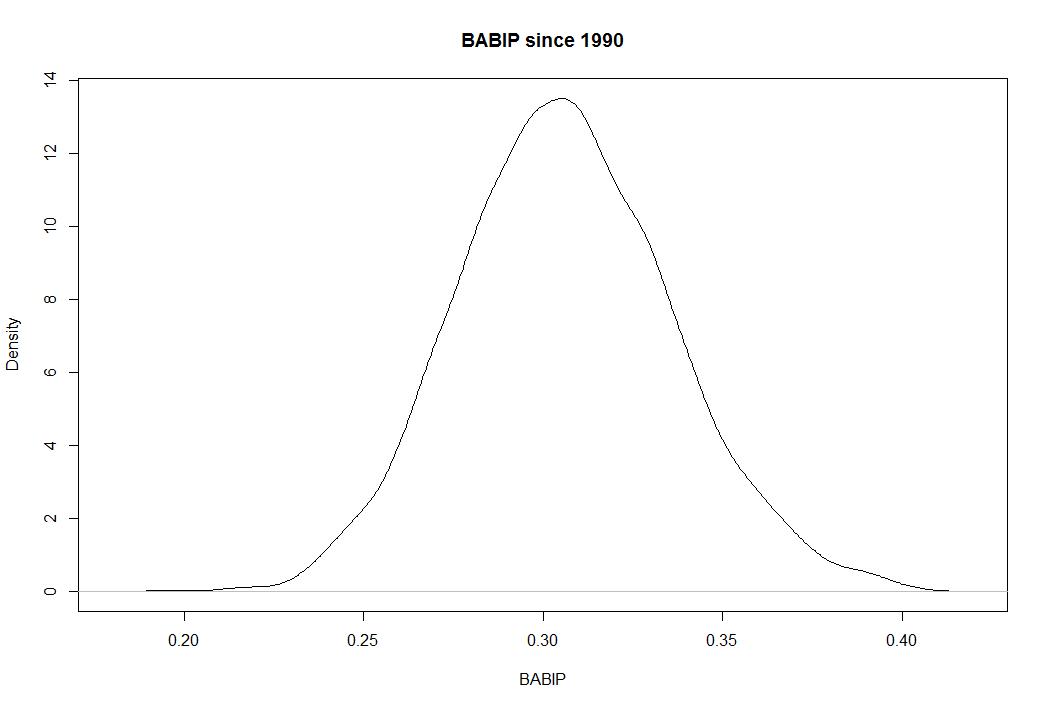
You can see how it centers on .300 and almost never extends beyond .250 and .350. But in small samples, it can be fluky and give you weird results that can inflate your batting average or other numbers. Let’s look at the last 14 days in MLB:

You’ll notice the normalized shape, but also notice the scale across the horizontal axis. Lots of players have BABIPs in the .400 and below .200 over the last two weeks, meaning lots of players are over and underperforming their true talent thanks to luck and random variation.
The takeaway is simple. BABIP is a place to look when deciding if a player’s improved (or worse) results are coming from a real change in skill or good fortune. If the BABIP looks funky, look closer. If the BABIP looks typical, there might be something real going on.
A New Way To Measure Relief Pitchers: SOEFA
I’ve long been a critic of the save statistic, and I don’t need to rehash why it’s the scourge of the baseball world, but relief pitching is still an important part of the game and we often struggle to properly measure it. Won/Loss record and saves tell you nothing about a player’s individual skill, especially not relievers, and even things like ERA don’t do a lot of good because relievers aren’t charged for runners they let in belonging to another pitcher and can get charged with runs allowed by the pitchers who come after.
Strikeouts, walks, and homeruns allowed (the basis of FIP) are good measurements, but FIP inherently strips away context. And context does matter for relief pitchers. It’s an elite reliever’s job to come in and strand runners, so strikeouts are good and homeruns are bad, but sequencing is really important and it matters a lot when they get outs and when they allow baserunners.
In a sense, FIP and similar statistics are good, but they aren’t perfect because they’re context neutral and we might want some context in reliever stats. Win Probability Added (WPA) is a typical way to fix this, but this feels too context dependent for me. WAR is always a nice combination of these kinds of measures, but WAR is a counting stat so how much a reliever is used matters a lot, and relievers are often used incorrectly.
My point here is not that I can come up with something better, but rather that I want to try to add something. I always look at reliever stats and find logical holes more often than with position players and starters. I want a reliever stat that measures context, considers the peripheral numbers, and also understands the luck involved. I didn’t find one out there that satisfied me, so I went to work inventing one.
I’ll say this. This isn’t perfect and I want to improve it. Flaws you may find in the method should not cause you to discount it, but rather to add to the discussion. This is a first crack. I hope you find it useful.
The Goal
So first, I started with a question: What is the job of a relief pitcher? Here was my answer:
- Strand runners
- Don’t allow baserunners
- If you allow baserunners, don’t let them score.
With that outlined, I went to work thinking about how to measure each and came up with the following statistic that I will call SOEFA, pronounced like “sofa.” It stands for Strand On-base ERA FIP Average and should be thought of as a way to measure relievers from your sofa. Yes, I have a whimsical side.
It has four components, let’s walk through them.
The Formula
First is Strand Rate+, which I calculated as what percent better or worse a reliever is from league average at stranding runners. League average is 70%, so if you strand 100% of your inherited runners, your Strand Rate+ is .43 because you are 43% better than league average.
Second, is your Expected OBP+ or xOBP+ which is your opponents on base percentage calculated as a percentage deviation from league average just like SR+, except that I regress your hits allowed based on league average BABIP because sometimes batters get lucky hits.
Third, is my version or ERA+, which is just like normal ERA- except I scale mine to zero instead of 100 like the major stat sites and invert it. Same principles regarding deviation from average applies. FIP+ is exactly the same, except I use FIP-. These numbers are park adjusted.
To combine them, I add SR+ to xOBP+ and then add ERA+ to get eSOEFA. I then repeat the same process and replace ERA+ with FIP+ to get fSOEFA. A pitcher’s SOEFA score is the average between the two.
The output gives you a number that sets league average at zero and ranges technically from negative infinity to about 2.5, but generally speaking you won’t see a reliever fall below -2.5. Basically it’s a -3 to 3 scale that puts good relievers on the plus side and bad ones on the negative side.
Additionally, at my discretion, relievers who have inherited fewer than five baserunners during the season (this number will likely be fluid based on where we are in the season) are given a league average SR+ so that if you don’t ever inherit runners you aren’t unfairly punished because you are not given sufficient opportunity to strand them or you are not given credit for an awesome strand rate if you strand the only runner you inherit.
I’m pretty happy with the first round of results. The first run of results came from stats entering June 25th and it generally lines up with my impression of the best performing relief pitchers in baseball. I have no idea if this stat is predictive or how long it takes to stabilize. Right now, it correlates with ERA and FIP at -.73 and -.75 despite the fact that each is only 1/6 of the input and the R squared is around .6 using it to predict FIP, if those kinds of things interest you.
It’s experimental. It’s meant to be fun and maybe helpful.
A word of note is that Fangraphs and B-R seem to use different cutoffs for which relievers “qualify,” so this output may be missing a few relievers. I’m sorry about that. The great thing about this statistic is that I can easily produce the number for any reliever in baseball in less than two minutes. If you want to know how a reliever measures up or how a reliever did during a given season, just ask and I can provide the number based on a handy program I wrote. Hit me on Twitter @NeilWeinberg44 and I’d be happy to provide the SOEFA for any reliever.
Thanks for reading and I welcome any feedback. Who knows, maybe this will work.
Below are the SOEFA for the vast majority of qualifying relievers up through 6/24/13. If you want to know the SOEFA of a reliever not on this list or would like an update score, please let me know.
| Rank | Player | Team | SOEFA |
| 1 | Sergio Romo | Giants | 0.99 |
| 2 | Jason Grilli | Pirates | 0.95 |
| 3 | Junichi Tazawa | Red Sox | 0.92 |
| 4 | Kevin Gregg | Cubs | 0.92 |
| 5 | Drew Smyly | Tigers | 0.9 |
| 6 | Joaquin Benoit | Tigers | 0.89 |
| 7 | Jordan Walden | Braves | 0.88 |
| 8 | Robbie Ross | Rangers | 0.87 |
| 9 | Mark Melancon | Pirates | 0.85 |
| 10 | Jesse Crain | White Sox | 0.83 |
| 11 | Edward Mujica | Cardinals | 0.79 |
| 12 | Brett Cecil | Blue Jays | 0.79 |
| 13 | Greg Holland | Royals | 0.75 |
| 14 | Oliver Perez | Mariners | 0.74 |
| 15 | Trevor Rosenthal | Cardinals | 0.74 |
| 16 | Kenley Jansen | Dodgers | 0.72 |
| 17 | Glen Perkins | Twins | 0.71 |
| 18 | Koji Uehara | Red Sox | 0.7 |
| 19 | Preston Claiborne | Yankees | 0.69 |
| 20 | Sam LeCure | Reds | 0.68 |
| 21 | Casey Janssen | Blue Jays | 0.64 |
| 22 | Mariano Rivera | Yankees | 0.63 |
| 23 | Luke Gregerson | Padres | 0.62 |
| 24 | Craig Kimbrel | Braves | 0.62 |
| 25 | Sean Doolittle | Athletics | 0.6 |
| 26 | Edgmer Escalona | Rockies | 0.56 |
| 27 | Tommy Hunter | Orioles | 0.56 |
| 28 | Brad Ziegler | Diamondbacks | 0.54 |
| 29 | Joe Nathan | Rangers | 0.53 |
| 30 | Joe Smith | Indians | 0.53 |
| 31 | Vin Mazzaro | Pirates | 0.51 |
| 32 | Jim Henderson | Brewers | 0.5 |
| 33 | James Russell | Cubs | 0.49 |
| 34 | Casey Fien | Twins | 0.48 |
| 35 | Tim Collins | Royals | 0.47 |
| 36 | Shawn Kelley | Yankees | 0.47 |
| 37 | Brian Matusz | Orioles | 0.46 |
| 38 | Addison Reed | White Sox | 0.46 |
| 39 | Tanner Scheppers | Rangers | 0.45 |
| 40 | Rafael Soriano | Nationals | 0.44 |
| 41 | Aroldis Chapman | Reds | 0.44 |
| 42 | Joel Peralta | Rays | 0.43 |
| 43 | Matt Reynolds | Diamondbacks | 0.43 |
| 44 | Brandon Kintzler | Brewers | 0.43 |
| 45 | Ryan Cook | Athletics | 0.42 |
| 46 | Chad Qualls | Marlins | 0.42 |
| 47 | Cody Allen | Indians | 0.4 |
| 48 | Andrew Miller | Red Sox | 0.4 |
| 49 | David Robertson | Yankees | 0.38 |
| 50 | Seth Maness | Cardinals | 0.36 |
| 51 | Bobby Parnell | Mets | 0.36 |
| 52 | Matt Belisle | Rockies | 0.36 |
| 53 | Josh Outman | Rockies | 0.36 |
| 54 | Rex Brothers | Rockies | 0.35 |
| 55 | Jonathan Papelbon | Phillies | 0.35 |
| 56 | Dale Thayer | Padres | 0.35 |
| 57 | Darren O’Day | Orioles | 0.33 |
| 58 | Justin Wilson | Pirates | 0.33 |
| 59 | Luke Hochevar | Royals | 0.31 |
| 60 | Grant Balfour | Athletics | 0.3 |
| 61 | John Axford | Brewers | 0.29 |
| 62 | Ernesto Frieri | Angels | 0.29 |
| 63 | Drew Storen | Nationals | 0.27 |
| 64 | Bryan Shaw | Indians | 0.26 |
| 65 | Nate Jones | White Sox | 0.26 |
| 66 | Luis Avilan | Braves | 0.25 |
| 67 | Anthony Varvaro | Braves | 0.25 |
| 68 | Anthony Swarzak | Twins | 0.24 |
| 69 | Paco Rodriguez | Dodgers | 0.24 |
| 70 | Jean Machi | Giants | 0.2 |
| 71 | Tyler Clippard | Nationals | 0.19 |
| 72 | Matt Thornton | White Sox | 0.19 |
| 73 | Steve Delabar | Blue Jays | 0.18 |
| 74 | Craig Stammen | Nationals | 0.17 |
| 75 | Tony Watson | Pirates | 0.17 |
| 76 | Pat Neshek | Athletics | 0.16 |
| 77 | Jamey Wright | Rays | 0.16 |
| 78 | J.P. Howell | Dodgers | 0.16 |
| 79 | Cesar Ramos | Rays | 0.15 |
| 80 | Alfredo Simon | Reds | 0.15 |
| 81 | Troy Patton | Orioles | 0.15 |
| 82 | Matt Lindstrom | White Sox | 0.14 |
| 83 | Jim Johnson | Orioles | 0.12 |
| 84 | Carter Capps | Mariners | 0.11 |
| 85 | Ryan Pressly | Twins | 0.11 |
| 86 | Steve Cishek | Marlins | 0.11 |
| 87 | Darin Downs | Tigers | 0.1 |
| 88 | Antonio Bastardo | Phillies | 0.09 |
| 89 | Charlie Furbush | Mariners | 0.07 |
| 90 | Brian Duensing | Twins | 0.07 |
| 91 | Yoervis Medina | Mariners | 0.07 |
| 92 | Jerry Blevins | Athletics | 0.07 |
| 93 | Tom Gorzelanny | Brewers | 0.06 |
| 94 | Jared Burton | Twins | 0.05 |
| 95 | Jose Veras | Astros | 0.05 |
| 96 | Joe Kelly | Cardinals | 0.05 |
| 97 | David Hernandez | Diamondbacks | 0.04 |
| 98 | Ryan Webb | Marlins | 0.04 |
| 99 | Aaron Loup | Blue Jays | 0.03 |
| 100 | Wesley Wright | Astros | 0.01 |
| 101 | Bryan Morris | Pirates | 0.01 |
| 102 | Burke Badenhop | Brewers | 0 |
| 103 | Dane de la Rosa | Angels | -0.02 |
| 104 | Adam Ottavino | Rockies | -0.04 |
| 105 | LaTroy Hawkins | Mets | -0.04 |
| 106 | Cory Gearrin | Braves | -0.06 |
| 107 | Joe Ortiz | Rangers | -0.08 |
| 108 | Wilton Lopez | Rockies | -0.08 |
| 109 | Brandon Lyon | Mets | -0.08 |
| 110 | J.J. Hoover | Reds | -0.08 |
| 111 | Mike Dunn | Marlins | -0.09 |
| 112 | Fernando Rodney | Rays | -0.1 |
| 113 | Hector Ambriz | Astros | -0.1 |
| 114 | Paul Clemens | Astros | -0.13 |
| 115 | Tom Wilhelmsen | Mariners | -0.13 |
| 116 | Matt Guerrier | Dodgers | -0.13 |
| 117 | Josh Roenicke | Twins | -0.17 |
| 118 | Jose Mijares | Giants | -0.21 |
| 119 | Michael Gonzalez | Brewers | -0.23 |
| 120 | Jonathan Broxton | Reds | -0.25 |
| 121 | Jake McGee | Rays | -0.25 |
| 122 | Matt Albers | Indians | -0.26 |
| 123 | A.J. Ramos | Marlins | -0.26 |
| 124 | Scott Rice | Mets | -0.29 |
| 125 | Nick Hagadone | Indians | -0.31 |
| 126 | Travis Blackley | Astros | -0.33 |
| 127 | Vinnie Pestano | Indians | -0.34 |
| 128 | George Kontos | Giants | -0.35 |
| 129 | Mike Adams | Phillies | -0.39 |
| 130 | Clayton Mortensen | Red Sox | -0.4 |
| 131 | Garrett Richards | Angels | -0.43 |
| 132 | Heath Bell | Diamondbacks | -0.46 |
| 133 | Esmil Rogers | Blue Jays | -0.5 |
| 134 | Ronald Belisario | Dodgers | -0.51 |
| 135 | Jeremy Affeldt | Giants | -0.55 |
| 136 | Brandon League | Dodgers | -0.55 |
| 137 | Jeremy Horst | Phillies | -0.58 |
| 138 | Kelvin Herrera | Royals | -0.67 |
| 139 | Carlos Marmol | Cubs | -0.72 |
| 140 | Huston Street | Padres | -0.82 |
| 141 | Anthony Bass | Padres | -0.94 |
| 142 | Hector Rondon | Cubs | -1.24 |
Stat(s) of the Week: Defensive Runs Saved and Ultimate Zone Rating
Since I’ve twice written above defense in the last week, it’s high time I actually explain these defensive stats. Luckily, this is quite easy to explain and understand. There are two primary defensive metrics that people use. Defensive Runs Saved (DRS) and Ultimate Zone Rating (UZR), which are based on people watching video of every play and computer algorithms.
You can learn exactly how each is calculate here, DRS and UZR. But you don’t need to know how to calculate them in order to understand what they mean. It’s important to learn about these because Fielding % is problematic stat because it doesn’t factor in a player’s range, so you can have a good fielding percentage if you don’t make errors because you never get to difficult balls. We need numbers that measure how good players are at preventing runs and avoiding errors isn’t the only way to do that.
The numbers are scaled to position, so league average at every position is zero and positive numbers are good and negative numbers are bad.
For example a player with a +5 DRS or +5 UZR is five runs better than league average at their position. 10 runs is equal to 1 Win Above Replacement (WAR). These are counting stats, so you accumulate them as the season goes on, although I believe they are only updated weekly on the more popular statistics websites.
You can use either DRS or UZR depending on your preference, but Baseball Reference uses DRS in their WAR and Fangraphs uses UZR in theirs. It’s a preference thing. I always use Fangraphs WAR on this site, but I interchange the defensive stats on occasion because I don’t really have a favorite. If there is no label on this site, it is UZR.
Additionally, you might see UZR/150, which is simply UZR scaled into a full season of games as if you played at your current pace for a whole season.
As a rule of thumb, 0 is average, -5/+5 is above or below average, -10/+10 is poor or great, -15/+15 is awful or elite. It is also important to know that these statistics take a while to become predictive, so small samples can cause problems with defensive numbers but they generally all a good description of what has happened, even if it doesn’t predict what will happen next.
Stat of the Week: Weighted Runs Above Average (wRAA)
When we talk about offensive statistics, the ones we usually talk about on New English D are wOBA and wRC+ which take the actual value of each offensive action and weight them properly, which OBP and SLG do not do. I encourage you to clink the links and read about those statistics if you have not already done so. However, those two statistics are rate stats and not counting stats. Rate stats tell you how well a player has performed while they’ve been on the field, but counting stats are also good for telling you how much value a player has actually added to his team.
If you have a 150 wRC+, but only have half the plate appearances of someone with a 120 wRC+, you’re not as valuable. You need to be both a good performer and a player who stays healthy and on the field. With that, I’ll introduce Weighted Runs Above Average (wRAA) to do just that. Weighted Runs Created (notice the absence of the plus sign) is a similar statistic, but it is just scaled differently. The concept is the same, but let’s stick with wRAA.
wRAA is the offensive component of Wins Above Replacement (WAR) and is based on wOBA and is rather simple to calculate if you have all of the necessary numbers.
((wOBA – League Average wOBA)/wOBA scale) * (PA)
A player’s wOBA and PA are pretty obvious and the league average and wOBA scale be found for each season quite easily here. The idea behind this statistic is how many runs a player is worth to his team above average and ten runs is equivalent to one WAR. Here is the full explanation from Fangraphs but the idea is pretty simple. How many runs above average has a player been worth to his team. Average, therefore, is 0 and anything above 10 is good and above 20 is great. It is also a counting stat, so players accumulate them throughout the season as opposed to wRC+ and wOBA which are rate stats.
I generally like rate stats better, but counting stats are an important comparison. Here’s a quick example:
Miguel Cabrera has a 193 wRC+ and .456 wOBA in 325 PA while Matt Tuiasosopo has a 186 wRC+ and .446 wOBA in 88 PA. Cabrera and Tuiasosopo have very similar rate stats, but you can distinguish their value based on how many PA they have using wRAA. Cabrera has 36.9 and Tuiasosopo has 9.3.
I wouldn’t tell you to use wRAA over wRC+ or wOBA, but it is nice to use in tandem if you’re trying to compare which players have been more valuable to their team, but stick with the rate stats if you care about determining who is actually the better player.
Stat of the Week: Run Expectancy
A point of contention among members of the baseball community is bunting. Most sabermetricians would tell you that the sacrifice bunt is overused because it gives away an out while a lot of on-field Dusty Baker/Harold Reynolds type people love bunting to move runners closer to the plate. I’m not here to argue for or against bunting, but rather to offer you a tool for determining the answer for yourself. This tool is a Run Expectancy Matrix.
The idea behind Run Expectancy is figuring out how many runs, on average, a team scores in a given situation (based on the number of outs and which bases are occupied). The values are based on long run averages and you can calculate them based on many years or a single year, but the ratios are generally going to be the same. Presented below is the matrix from 2012. What you see in the grid is the expected number of runs a team will score given the situation as presented by the top row and left column. You can use the RE Matrix to determine which strategic move is best for you.

So let’s use an example. Runner on 1st base, no outs. At this point, the team is expected to score .8577 runs this inning because, on average, teams have scored that many runs in the inning after those situations have occurred. If we were to sacrifice bunt in this situation, we would move to runner on 2nd, 1 out, which has an expected run value of .6551. That’s obviously less than .8577, so the sacrifice bunt in that situation is not the right play on average. You can play around with other situations on your own.
An important caveat is that this chart is context neutral and reflects averages. If the baserunner is Austin Jackson and the guy bunting is Miguel Cabrera, you’re hurting yourself more than if the runner is Victor Martinez and the bunter is Ramon Santiago. You should be more willing to give up an out to move a runner if the batter is more likely to make an out. However, that doesn’t mean it’s necessarily ever the right play to give up the out. A pitcher who hits .150 is almost definitely going to make an out, so you want him to move the runner up, but Miguel Cabrera is pretty likely going to get a hit relative to average, so you don’t want him intentionally making an out.
I don’t mean to suggest that you should take these numbers as gospel, but rather that you should be aware of which situations lead to the most runs and which situations you want to get yourself into if possible. The takeaway here is that we know how many runs a team is likely to score in a given situation and we can make some sort of educated prediction about what will happen if we do something else. Context matters, but this matters too.
I’m generally not a fan of the sacrifice bunt (or conversely the intentional walk), but there are occasional situations in which it makes sense. This RE Matrix should help you better understand which situations call for which moves.
As always, if you have questions about how this works or how to use it, feel free to comment or contact us. Also, please let us know if there is a statistic or sabermetric concept you’d like to learn about and we’d be happy to cover it.
Stat of the Week: Expected Fielding Independent Pitching (xFIP)
Generally, I’ve been a little light on “weekly” updates to this feature, but I generally write at least one statistically informative post a week, even if it doesn’t actually follow the mold I’ve laid out. Today, I’ll try to write that wrong with an introduction to the very useful Expected Fielding Independent Pitching (xFIP).
You may recall my introduction to Fielding Independent Pitching (FIP) some months ago and my frequent use of the metric on the site. You can read my introduction to FIP or Fangraphs’ primer to catch up, but I’ll outline the basic concept because it carries over.
We use FIP because ERA is not a reflection of a pitcher’s individual performance because he cannot control what his defense does once the ball is put in play. Two pitchers who are carbon copies of each other will perform differently if you put them in front of the Dbacks defense (currently the league’s best) and the Angels defense (one of the league’s worst so far) despite throwing identical pitches to identical hitters. ERA is a reflection of the team as a whole, not just the pitcher.
In steps FIP or a class of numbers coming from this idea, to measure a pitcher’s performance based only on what we know he can control. FIP takes strikeouts, walks, and homeruns and uses historic run values to calculate a number on the same scale as ERA so that you can see which pitchers are succeeding in the areas of the game they can control. Generally speaking, defense evens out over a long enough period and ERA, FIP, and our new friend xFIP will converge toward each other.
The FIP formula looks like this:
FIP = ((13*HR)+(3*(BB+HBP))-(2*K))/IP + constant
So what exactly is xFIP? xFIP, as you can read about on Fangraphs, takes this one more step. xFIP is the same as FIP except it normalizes HR/FB rate to give you a number that better predicts future performance.
It’s actually pretty simple, just stay with me. Generally speaking, we’ve found that the percentage of a pitcher’s flyballs that are hit for homeruns will converge toward about 10% and that large variations from that number are not sustainable. If you allow more flyballs, you’ll allow more homeruns, and that will cost you in FIP and xFIP, but if you’re allowing half of your flyballs to go for homeruns, it’s likely that won’t happen for very long.
So xFIP looks like this:
xFIP = ((13*(Flyballs * League-average HR/FB rate))+(3*(BB+HBP))-(2*K))/IP + constant
As you can see, it’s the same formula, but it takes your flyball rate and multiplies that by the league average HR/FB rate to get a more predictive version of your HR rate going forward. xFIP is one of the best indicators of future performance we have and it is very useful in evaluating which pitchers are getting lucky and which pitcher’s are actually performing in line with their skills.

If we scan the Tigers 2013 leaderboard right now (digits truncated), you can get a sense of how this works. As expected, all of the Tigers have better FIP than their ERA because they play in front of a poor defense, but all of their xFIP are slightly higher than their FIP (except for Porcello) because they are allowing a lower than average HR/FB rate. Porcello, on the other hand, has very unlucky 21% HR/FB rate, so his xFIP is better than his FIP. Again, xFIP correlates better with future performance than almost any other ERA estimator.
Personally, I like to look at FIP to see how a pitcher is doing and use xFIP to see how fluke-y his homerun rate is. They’re both good metrics and they are both better indicators of individual performance than ERA.
Want to learn about a statistic? Request one for the next edition in the comments section or on Twitter @NeilWeinberg44. If you’re looking to catch up on sabermetrics, check out New English D’s posts on FIP, WAR, wOBA, wRC+, and ISO.
On Defense and Unearned Runs: ERA Isn’t the Answer
Last night, Justin Verlander was not at his best, but his overall line looked worse than it was because Torii Hunter made two poor plays in right that cost Verlander two runs, but neither was ruled an error. So Verlander’s ERA goes up because of poor defense even though conventional wisdom is that the “earned” part of ERA factors out your defense making mistakes behind you.
It does and it doesn’t. You don’t get charged for runs that come from errors but you do get penalized when the official scorer makes a mistake (as we saw last night) and when your defensive players do not make a play they should have even though it does not qualify as an error. Sabermetricians have devised other metrics like FIP, xFIP, SIERA, and others to stand in for ERA with a focus on elements of the game that pitchers can control because they have no control of what happens once contact is made. (Read my explanation of FIP for more specific information)
Today, I’d like to offer a little concrete evidence for why ERA doesn’t capture a pitcher’s value. Let’s take an independent measure of defense (Fangraph’s aggregate Fld score) and compare it to the number of unearned runs a team allows (or the percentage of a team’s runs that are unearned).
I haven’t looked back into history, but for 2013 the relationship is nonexistent. For the raw number of unearned runs, the results are not statistically significant and are substantively small. On average a team needs to increase its Fld score (range -21 to 18 so far) by about 7 to eliminate a single unearned run on average (range 5 to 25 so far). On average, from worst to first in Fld you can move only 20% of the range of unearned runs. This tells us that the strength of one’s defense does not predict the number of unearned runs allowed. The results are the same if we control for the total number of runs a team has allowed.
Here it is in graphical form:

As you can see, the number of unearned runs has almost no relationship with Fld and if you squint hard enough can only come up with the slightest negative tilt. Basically, what this is showing you is that the difference between your runs allowed and the runs you get shoved into your ERA do not depend on the quality of your defense, it depends on the official scorer and it depends on a lot of other things that have nothing to do with a pitcher’s skill or performance.
This is all by way of saying that ERA is not a good measure of a pitcher’s true skill level. It’s not a bad place to start, but if you look at the Won-Loss Record and ERA, you’re getting very little useful information. Expand your horizon to K/9, BB/9, HR/FB, FIP, xFIP, and other statistics and metrics that enrich the game.
ERA attempts to capture the pitcher’s performance in isolation but it doesn’t. The defense and the official scorer play huge roles in determining that number. If you want to judge a pitcher by themselves, you need to look deeper.
If you’re interested in learning more, I encourage you to visit the Fangraphs Glossary or to post questions in the comment section. I’d be happy to explain or interpret any and all statistics about which you are curious.
Doug Fister and Something We’ve Never Seen Before

Doug Fister is doing something kind of amazing so far this season. He’s hitting more batters than he is walking. Through 8 starts and 50 innings, Fister has hit 10 batters and walked 8 for a HBP-BB = 2. This is remarkable just because it’s a crazy thing, but it’s also remarkable because it has never happened before. (Editor’s Note: As of 9/2, Fister has hit 16 and walked 37 in 179.2 IP, he currently ranks 3rd all time and is 5 behind the leader. As of August 7th, this is the BB% to HBP% of every season in MLB history. Fister is in red).
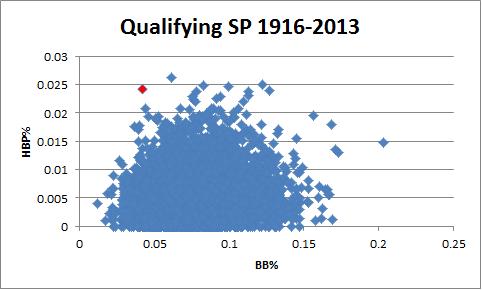
Granted, Fister is only about a quarter of the way through his season and this can’t possibly keep up, but it’s worth noting how crazy this is. Over the course of an entire season, for qualified pitchers, no one has ever hit more batters than they have walked. The MLB record holder is Carlos Silva in 2005 who hit 3 batters and walked 9 in 188.1 innings. That walk rate itself is just fun to look at, but it’s beside the point. No one has ever complete a full season in which they have hit more batters than they have walked and the closest anyone has ever come is a differential of 6.
Now certainly, you will call attention to a small sample size and that over 50 innings pretty much anything can happen. And that’s true, but it doesn’t escape the fact that in 2013, no one else is hitting more batters than they are walking. Not Wainwright, not Colon, not Haren. None of the great control artists of our time are doing this even in the same small sample as Fister. I’m sure there are instances of pitchers doing this over similarly small stretches in history, but they would be very hard to find.
Think of it this way, from 1900-2013, the average pitcher hits 5 batters a season and walks 68. Even in the smallest of samples, it’s pretty extraordinary to find a period in which a pitcher is hitting more than he is walking, and these statistics include eras in which walks were much less common. Even in data that includes the 2013, which will bias the data away from these results, I calculate a chance that a pitcher would finish a season with more HBP than BB between 0.5 and 2 percent if this process played out at random. Here is a graph of HBP-BB with 2013 included, which will include pitchers like Wainwright this year who just haven’t walked many batters because they are good and it’s only been six weeks:

For now, Fister is on pace for a record all his own.
The Greg Maddux Way: A Simple Statistic
The great Greg Maddux (355-227, 3.16 ERA, 3.26 FIP, 114.3 WAR) once said the key to pitching is throwing a ball when the batter is swinging and throwing a strike when the batter is taking. That’s a pretty good general rule, but an astute observer would certainly recognize that a pitcher isn’t really equipped to predict such a thing terribly well.
But this did get me thinking, is there something to this idea despite other intervening reasons that confound it? Certainly, if you have a crazy slider that no one can hit, it doesn’t really matter where you throw it. Or a fastball that the hitter can’t handle. It’s also not like where you choose to throw the pitch and if the hitter swings are independent of each other.
So this is an exercise, plain and simple. The Maddux idea is a good one in principle, but it’s not that simple. We know that, he knows that, let’s just look into it for fun.
I drew from the 2012 season and looked at qualified pitchers (n = 88). I developed a simple statistics to quantify how Maddux-y they pitched.
mPercentage = (O-Swing% – League Average O-Swing%) + (-1)*(Z-Swing%-League Average Z-Swing%)
O-Swing% is the percent of the time a pitcher induced the opposing hitter to swing at a pitch he threw outside the zone and Z-Swing% is the same statistic for pitches inside the zone. The -1 is included so that both Maddux attributes are positive and can be added together without converging toward zero.
The results were pretty surprising because some pitchers at the top of the list are awesome and some are average and some are terrible. There isn’t a ton of correlation between this statistic and actual production. The two league leaders in 2012 mPercentage are Joe Blanton and Chris Sale. Cliff Lee is 4th, which sounds right, but Verlander is 42nd.

If you take a wider angle and regress ERA or FIP on mPercentage, you find that on average a 1% increase (i.e. 5% to 6%) decreases your ERA or FIP by 0.06 runs, which is not very much at all. mPercentage is statistically significant in both models, but not substantively significant at all. (The R squared is less than .11 in both.)
So what this tells us is that the Maddux Method doesn’t really exist in practice. Pitchers who induce swings on balls and takes on strikes are no more successful than those who do not. However, there is a obviously a two-way street at play here like I mentioned earlier. The Maddux Method works perfectly in theory, but we have an observation issue given that Justin Verlander’s strikes are much harder to hit than Joe Blanton’s, so he can throw more of them.
I like the Maddux philosophy of pitching, but it isn’t enough. You also need to have good stuff.
